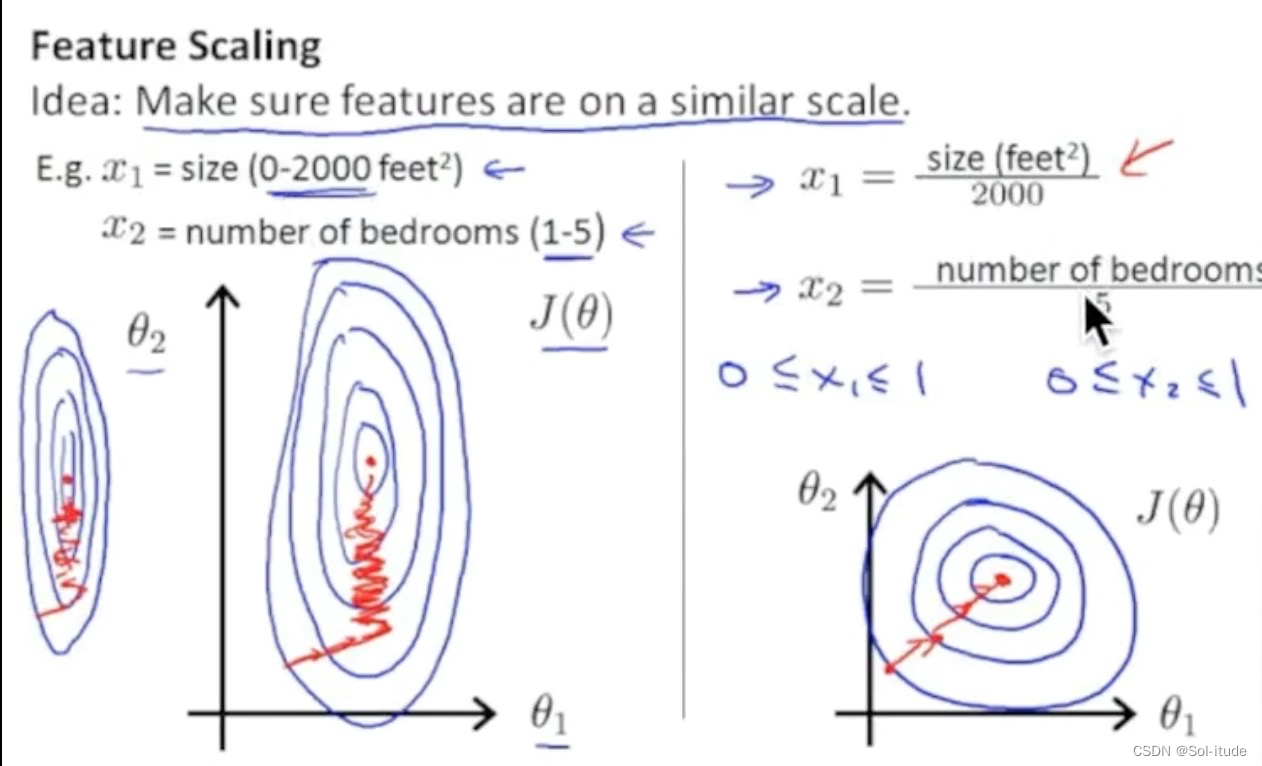
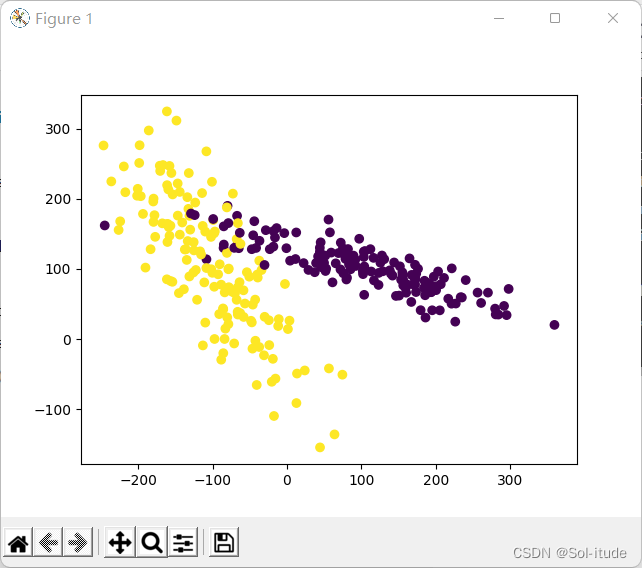
from sklearn import preprocessing import numpy as np from sklearn.model_selection import train_test_split##从sklearn数据库导入函数 from sklearn.datasets._samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt
from sklearn import preprocessing import numpy as np from sklearn.model_selection import train_test_split##从sklearn数据库导入函数 from sklearn.datasets._samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt
from sklearn import preprocessing import numpy as np from sklearn.model_selection import train_test_split##从sklearn数据库导入函数 from sklearn.datasets._samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt