原视频链接:3. 零基础入门PyTorch之线性回归【逐行代码讲解】
原文章链接:【PyTorch修炼】零基础入门PyTorch之线性回归【逐行代码讲解】
线性回归其实就是
y=kx+b
但是需要注意的是,这里所有的未知量都是一个矩阵而不是一个数,k是权重,b是偏差
要求:
- 数据都是tensor类型 如果有batch_size需要用dataloader去装这个数据
- 建立 model
- 完成训练过程 ->进行前向传播 ->利用loss反向传播 ->优化器进行优化
- 用matlplotlib进行数据可视化
程序示例
导入库
1
2
3
| import torch
import torch.nn as nn
import matplotlib.pyplot as plt
|
写出函数并画图
1
2
3
4
5
6
7
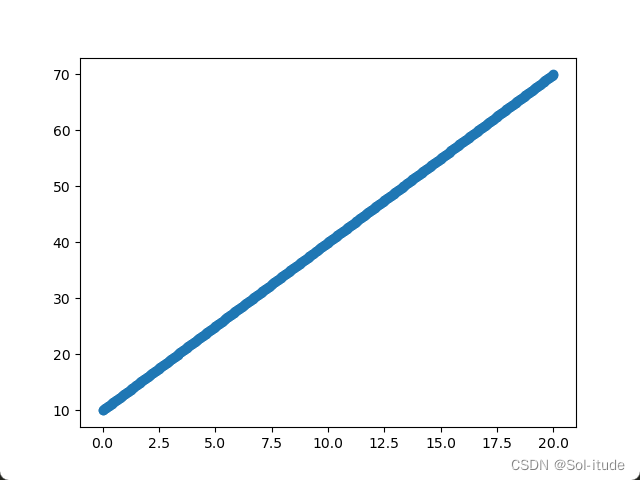
| x=torch.linspace(0,20,500)
k=3
b=10
y=k*x+b
plt.scatter(x.data.numpy(),y.data.numpy())
plt.show()
|
输出结果:
现在我们把写的函数都注释掉,来用机器学习拟合这条线
自己做一个数据集
1
2
3
4
5
6
7
| x=torch.rand(512)
noise=0.2*torch.randn(x.size())
k=3
b=10
y=k*x+b+noise
plt.scatter(x.data.numpy(),y.data.numpy())
plt.show()
|
输出结果:

构建神经网络
1
2
3
4
5
6
7
8
9
| class LinearModel(nn.Module):
def __init__(self,in_fea,out_fea):
super(LinearModel, self).__init__()
self.output=nn.Linear(in_features=in_fea,out_features=out_fea)
def forward(self,x):
x=self.output(x)
return x
input_x=torch.unsqueeze(x,dim=1)
input_y=torch.unsqueeze(y,dim=1)
|
构建损失函数和优化器
1
2
3
| model=LinearModel()
loss_func=nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.02)
|
准备画图
开始训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| for step in range(20):
pred=model(input_x)
loss=loss_func(pred,input_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step %10 ==0:
plt.cla()
plt.scatter(input_x.data.numpy(),input_y.data.numpy())
plt.plot(input_x.data.numpy(),pred.data.numpy(),'r-',lw=5)
[w,b]=model.parameters()
plt.text(0,0.5,'loss=%.4f,k=%.2f,b=%.2f'%(loss.item(),k.item(),b.item()))
plt.pause(1)
plt.ioff()
plt.show()
|
输出结果:
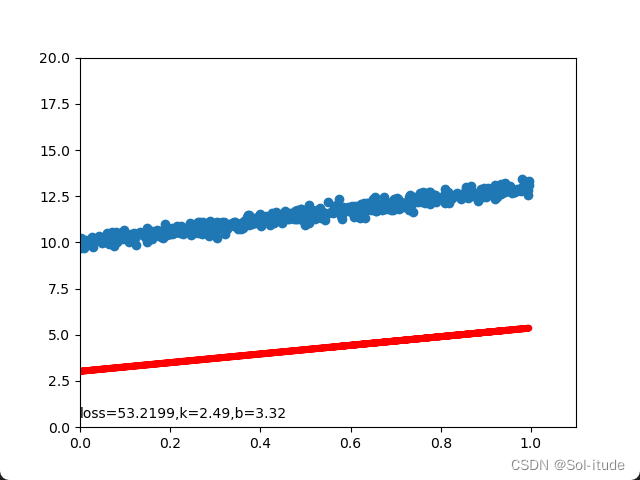
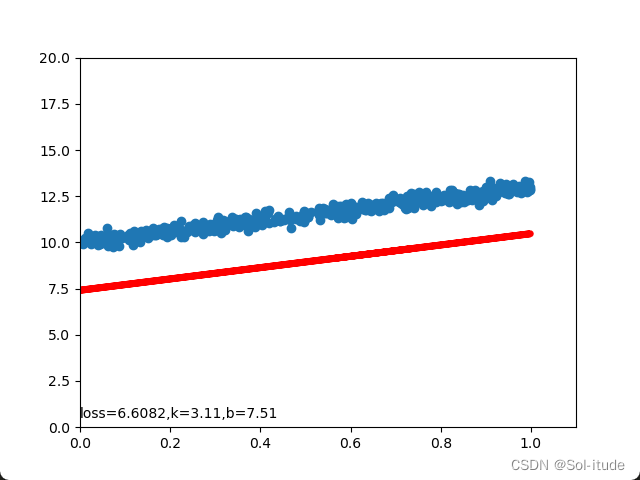
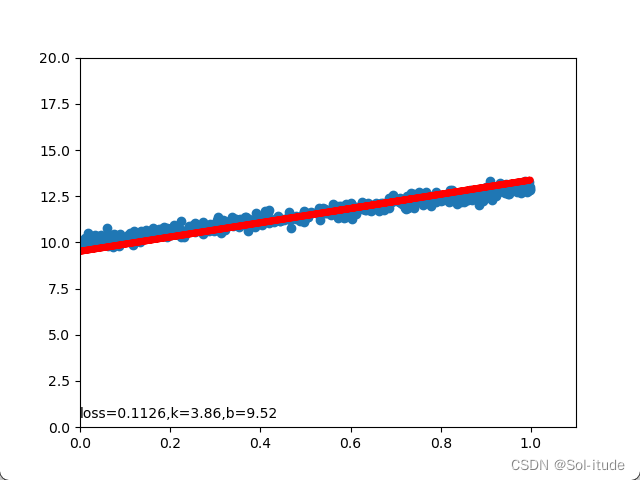
可以看到红线正在逐渐拟合
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import torch
import torch.nn as nn
import matplotlib.pyplot as plt
x=torch.rand(512)
noise=0.2*torch.randn(x.size())
k=3
b=10
y=k*x+b+noise
class LinearModel(nn.Module):
def __init__(self,in_fea,out_fea):
super(LinearModel, self).__init__()
self.output=nn.Linear(in_features=in_fea,out_features=out_fea)
def forward(self,x):
x=self.output(x)
return x
input_x=torch.unsqueeze(x,dim=1)
input_y=torch.unsqueeze(y,dim=1)
model=LinearModel(1,1)
loss_func=nn.MSELoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.02)
plt.ion()
for step in range(200):
pred=model(input_x)
loss=loss_func(pred,input_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step %10 ==0:
plt.cla()
plt.scatter(input_x.data.numpy(),input_y.data.numpy())
plt.plot(input_x.data.numpy(),pred.data.numpy(),'r-',lw=5)
plt.xlim(0, 1.1)
plt.ylim(0, 20)
[w,b]=model.parameters()
plt.text(0,0.5,'loss=%.4f,k=%.2f,b=%.2f'%(loss.item(),w.item(),b.item()))
plt.pause(1)
plt.ioff()
plt.show()
|
